Building a Better Profanity Detection Library with scikit-learn
Why existing libraries are uninspiring and how I built a better one.
A few months ago, I needed a way to detect profanity in user-submitted text strings:
I ended up building and releasing my own library for this purpose called profanity-check.
Of course, before I did that, I looked in the Python Package Index (PyPI) for any existing libraries that could do this for me. The only half decent results for the search query “profanity” were:
- profanity (the ideal package name)
- better-profanity: “Inspired from package profanity of Ben Friedland, this library is much faster than the original one.”
- profanityfilter (has 31 Github stars, which is 30 more than most of the other results have)
- profanity-filter (uses Machine Learning, enough said?!)
Third-party libraries can sometimes be sketchy, though, so I did my due diligence on these 4 results.
profanity, better-profanity, and profanityfilter
After a quick dig through the profanity repository, I found a file named wordlist.txt:
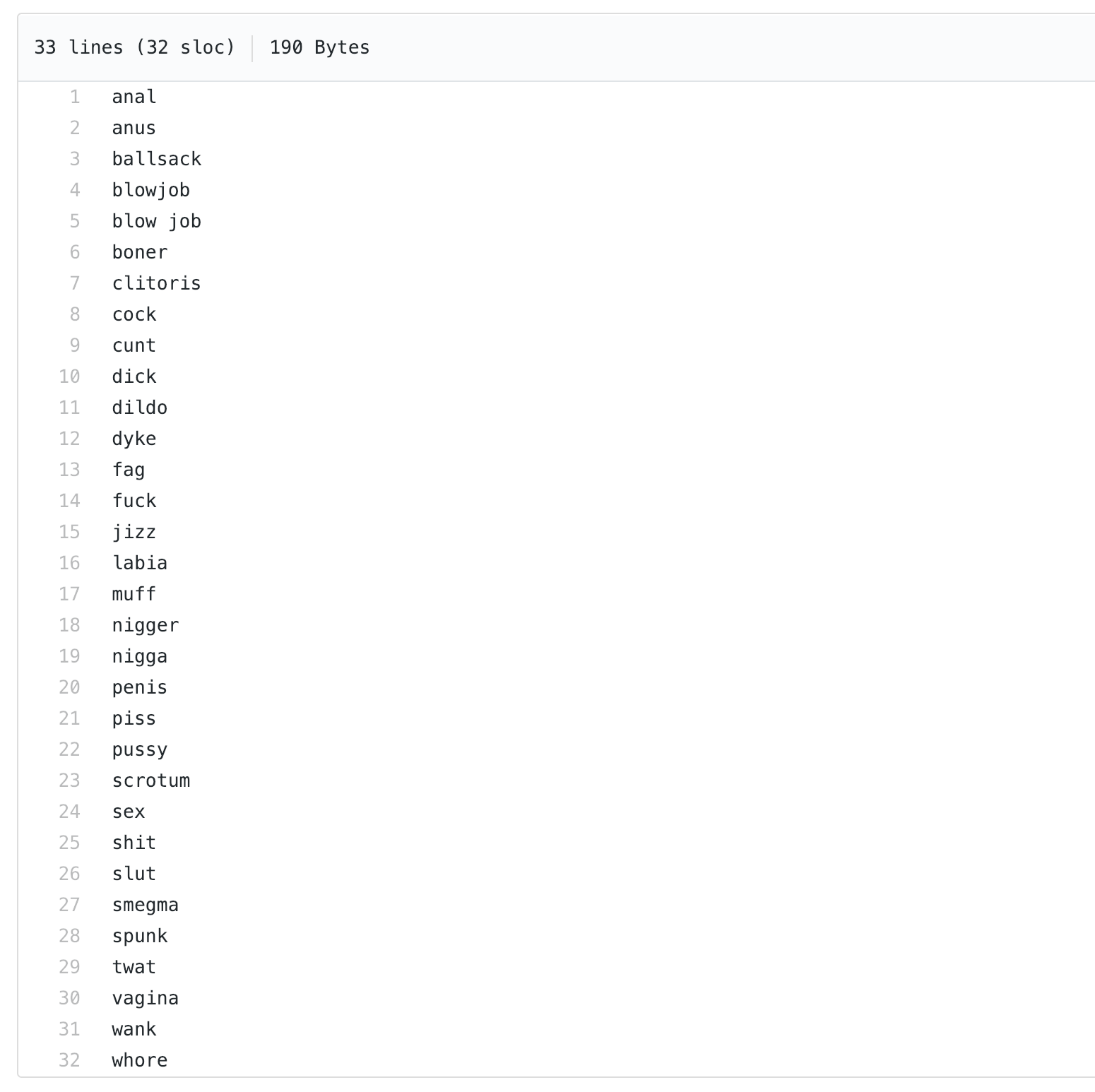
The entire profanity library is just a wrapper over this list of 32 words! profanity detects profanity simply by looking for one of these words.
To my dismay, better-profanity and profanityfilter both took the same approach:
better-profanityuses a 140-word wordlistprofanityfilteruses a 418-word wordlist
This is bad because profanity detection libraries based on wordlists are extremely subjective. For example, better-profanity’s wordlist includes the word “suck.” Are you willing to say that any sentence containing the word “suck” is profane? Furthermore, any hard-coded list of bad words will inevitably be incomplete — do you think profanity’s 32 bad words are the only ones out there?

Having already ruled out 3 libraries, I put my hopes on the 4th and final one: profanity-filter.
profanity-filter
profanity-filter uses Machine Learning! Sweet!
Turns out, it’s really slow. Here’s a benchmark I ran in December 2018 comparing (1) profanity-filter, (2) my library profanity-check, and (3) profanity (the one with the list of 32 words):
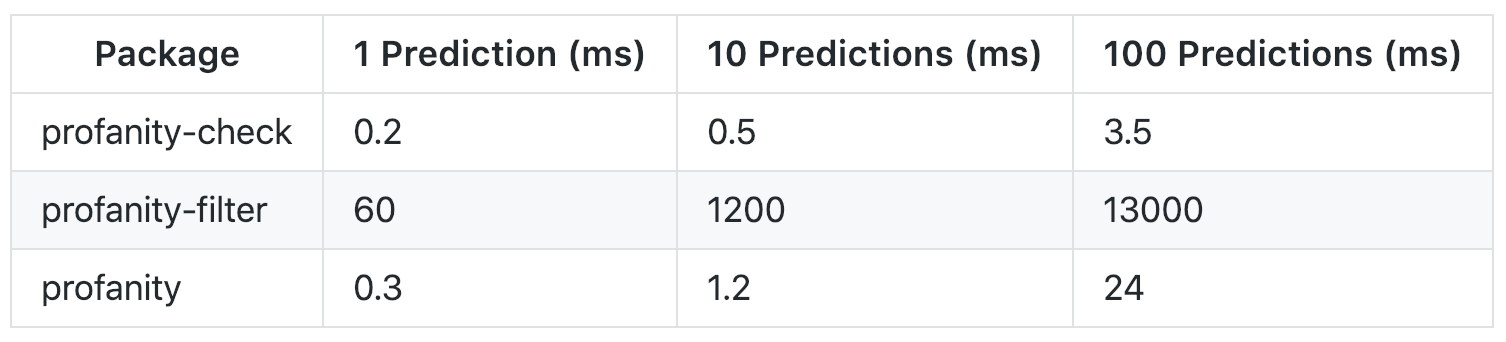
I needed to be able to perform many predictions in real time, and profanity-filter was not even close to being fast enough. But hey, maybe this is a classic tradeoff of accuracy for speed, right?
Nope.

None of the libraries I’d found on PyPI met my needs, so I built my own.
Building profanity-check, Part 1: Data
I knew that I wanted profanity-check to base its classifications on data to avoid being subjective (read: to be able to say I used Machine Learning). I put together a combined dataset from two publicly-available sources:
- the “Twitter” dataset from t-davidson/hate-speech-and-offensive-language, which contains tweets scraped from Twitter.
- the “Wikipedia” dataset from this Kaggle competition published by Alphabet’s Conversation AI team, which contains comments from Wikipedia’s talk page edits.
Each of these datasets contains text samples hand-labeled by humans through crowdsourcing sites like Figure Eight.
Here’s what my dataset ended up looking like:
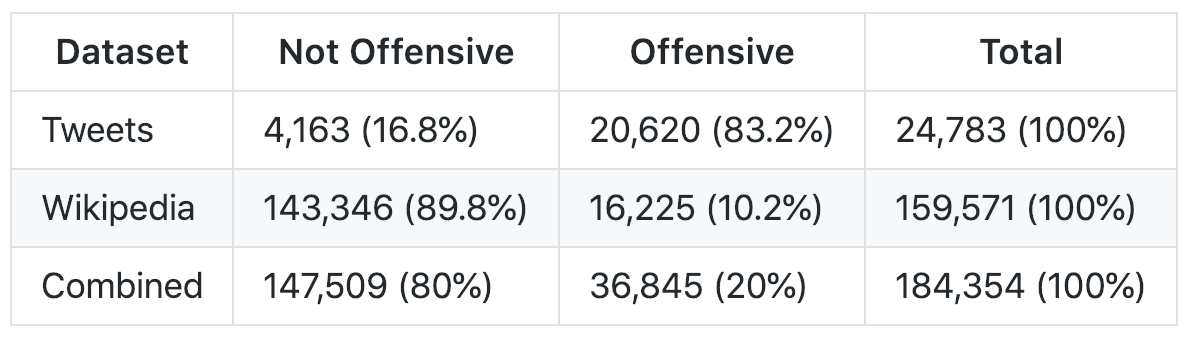
The Twitter dataset has a column named
classthat’s 0 if the tweet contains hate speech, 1 if it contains offensive language, and 2 if it contains neither. I classified any tweet with aclassof 2 as “Not Offensive” and all other tweets as “Offensive.”
The Wikipedia dataset has several binary columns (e.g.
toxicorthreat) that represent whether or not that text contains that type of toxicity. I classified any text that contained any of the types of toxicity as “Offensive” and all other texts as “Not Offensive.”
Building profanity-check, Part 2: Training
Now armed with a cleaned, combined dataset (which you can download here), I was ready to train the model!
I’m skipping over how I cleaned the dataset because, honestly, it’s pretty boring— if you’re interested in learning more about preprocessing text datasets check out this article or this post.
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.calibration import CalibratedClassifierCV
from sklearn.svm import LinearSVC
from sklearn.externals import joblib
# Read in data
data = pd.read_csv('clean_data.csv')
texts = data['text'].astype(str)
y = data['is_offensive']
# Vectorize the text
vectorizer = CountVectorizer(stop_words='english', min_df=0.0001)
X = vectorizer.fit_transform(texts)
# Train the model
model = LinearSVC(class_weight="balanced", dual=False, tol=1e-2, max_iter=1e5)
cclf = CalibratedClassifierCV(base_estimator=model)
cclf.fit(X, y)
# Save the model
joblib.dump(vectorizer, 'vectorizer.joblib')
joblib.dump(cclf, 'model.joblib')Two major steps are happening here: (1) vectorization and (2) training.
Vectorization: Bag of Words
I used scikit-learn’s CountVectorizer class, which basically turns any text string into a vector by counting how many times each given word appears. This is known as a Bag of Words (BOW) representation. For example, if the only words in the English language were the, cat, sat, and hat, a possible vectorization of the sentence the cat sat in the hat might be:
![“the cat sat in the hat” -> [2, 1, 1, 1, 1]](https://cdn-images-1.medium.com/max/1600/1*sbnts1u_QFB_V-X5DSC3pg.png)
The ??? represents any unknown word, which for this sentence is in. Any sentence can be represented in this way as counts of the, cat, sat, hat, and ???!
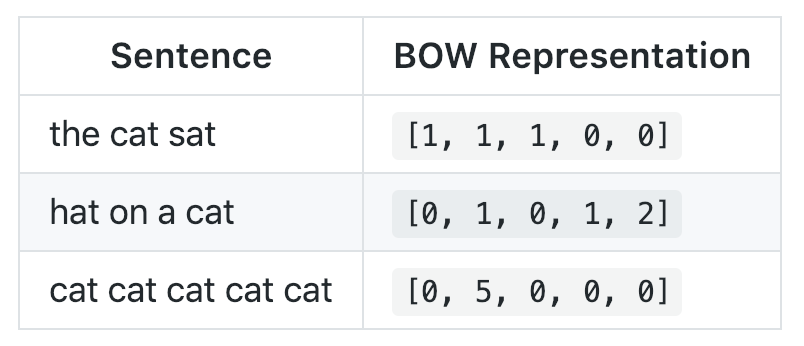
Of course, there are far more words in the English language, so in the code above I use the fit_transform() method, which does 2 things:
- Fit: learns a vocabulary by looking at all words that appear in the dataset.
- Transform: turns each text string in the dataset into its vector form.
Training: Linear SVM
The model I decided to use was a Linear Support Vector Machine (SVM), which is implemented by scikit-learn’s LinearSVC class. This post and this tutorial are good introductions if you don’t know what SVMs are.
The CalibratedClassifierCV in the code above exists as a wrapper to give me the
predict_proba()method, which returns a probability for each class instead of just a classification. You can pretty much just ignore it if that last sentence made no sense to you, though.
Here’s one (simplified) way you could think about why the Linear SVM works: during the training process, the model learns which words are “bad” and how “bad” they are because those words appear more often in offensive texts. It’s as if the training process is picking out the “bad” words for me, which is much better than using a wordlist I write myself!
A Linear SVM combines the best aspects of the other profanity detection libraries I found: it’s fast enough to run in real-time yet robust enough to handle many different kinds of profanity.
Caveats
That being said, profanity-check is far from perfect. Let me be clear: take predictions from profanity-check with a grain of salt because it makes mistakes. For example, its not good at picking up less common variants of profanities like “f4ck you” or “you b1tch” because they don’t appear often enough in the training data. You’ll never be able to detect all profanity (people will come up with new ways to evade filters), but profanity-check does a good job at finding most.
profanity-check
profanity-check is open source and available on PyPI! To use it, simply
$ pip install profanity-checkHow could profanity-check be even better? Feel free to reach out or comment with any thoughts or suggestions!
This article was originally posted on Medium.